
美国dot雷竞技官网最新版本一键获取 公司下属的dot雷竞技官网最新版本一键获取 MVE品牌焊接绝热气瓶系列,MVE液氮罐杜瓦瓶产品具有超过40年的生产历史,其制造中心拥有多项技术。用于生产dot雷竞技官网最新版本一键获取 杜瓦瓶,MVE液氮罐杜瓦瓶始终追求产品质量。

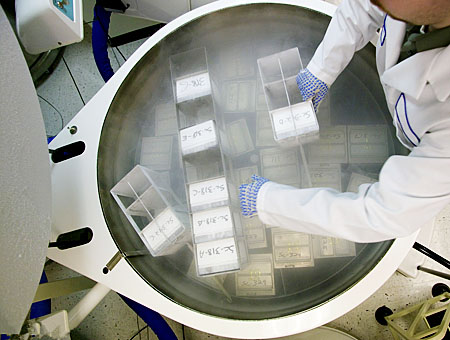
dot雷竞技官网最新版本一键获取 金凤液氮罐中小型储存液氮罐是采用高强度铝合金制造的储存型液氮容器。金凤液氮罐采用高真空绝热设计。多种不同型号可供选择。方提桶型液氮罐主要用以储存细胞样品用于生命科学领域.
Chart MVE 针对深冷储存的解决方案使得各行业能够更有效地利用深冷技术。

Copyright © 2001,Dota2雷电竞下载安装 /,All rights reserved 京ICP备17012785号-7 北京德世科技有限公司 版权所有






